
Systems Saturday 2: Kafka
The backbone of modern data pipelines

Picture this: you’re running a global e-commerce platform. Every click, purchase, or inventory update from millions of users worldwide needs to zip through your systems in real-time. One service handles payments, another updates inventory, and a third powers your recommendation engine. All while your analytics team demands instant insights to spot trends. Without a way to coordinate this data deluge, you’re staring at a digital traffic jam: dropped messages, lagging updates, or worse, a system crash. Enter Apache Kafka, the unsung hero that keeps this chaos in check.
At its core, Apache Kafka is a distributed streaming platform that handles massive volumes of data with the grace of a seasoned conductor. Kafka is a robust system for collecting, storing, and delivering data in real-time, across applications, services, and even continents. Whether it’s powering Netflix’s recommendation engine or helping LinkedIn process billions of app events daily, Kafka is the backbone of modern data pipelines.
The Problem Kafka Solves
Modern applications drown in data. Every click on a website, every sensor ping, every stock trade generates a flood of events that need to be processed, routed, and analyzed, often in real-time. Uber, for example, handles about 40 million reads per second. Petabytes, even exabytes of data. Without a way to manage this deluge, systems buckle, data gets lost, or insights arrive too late to matter.
Traditional tools just can’t keep up. Many databases, built for structured storage and queries, choke on the velocity and variety of real-time data streams. Message queues like RabbitMQ excel at shuttling messages between two points but struggle to scale across distributed systems or retain data for later use. File systems, meanwhile, are like trying to run underwater — clunky, slow, and not well suited for the job.

Picture a frenzied postal office where letters pile up unsorted, some get misplaced, and others arrive days late. That’s the pre-Kafka world of data pipelines: chaotic, fragile, and prone to failure.
Kafka changes the game. It’s a distributed streaming platform designed to handle data at massive scale, with low latency and ironclad reliability. Unlike traditional queues that delete messages after delivery, Kafka stores data persistently, letting systems process it now or later. Unlike databases, it’s optimized for high-throughput streams, not complex queries. And unlike file systems, it’s built for distributed, real-time access.
Kafka’s Core Concepts
Kafka’s power lies in its elegant design, built around a handful of core concepts that make it both simple and scalable.
One of the first abstractions: topics. These are like labeled buckets where data lives. For example, imagine a topic called “orders” that holds every purchase event from an e-commerce site. Each message a tidy record of who bought what, when. Producers, the data senders, pump messages into topics. Consumers are able to subscribe to these topics, pulling data from topics to process it, whether for analytics, logging, or triggering other actions.
Kafka runs on brokers. Brokers are the servers that form a Kafka cluster, responsible for storing and managing data. Each broker holds a portion of the data, and together they distribute the workload. Topics are divided into partitions, which allow data to be split across brokers for parallel processing, boosting throughput and scalability. Replication ensures fault tolerance by duplicating each partition across multiple brokers, so data remains accessible even if a broker fails.
Consumer groups enable efficient data consumption. Multiple consumers can join a group to process a topic’s partitions in parallel, with each consumer handling a subset of partitions to avoid duplicate processing. Kafka’s log-based architecture underpins it all: messages are appended to an immutable, ordered log within each partition. This design enables fast sequential writes, persistent storage, and flexible retention periods, allowing systems to process data in real-time or revisit it later as needed.
Consider the following example architecture diagram, where the partitions’ respective topic is denoted by the color.
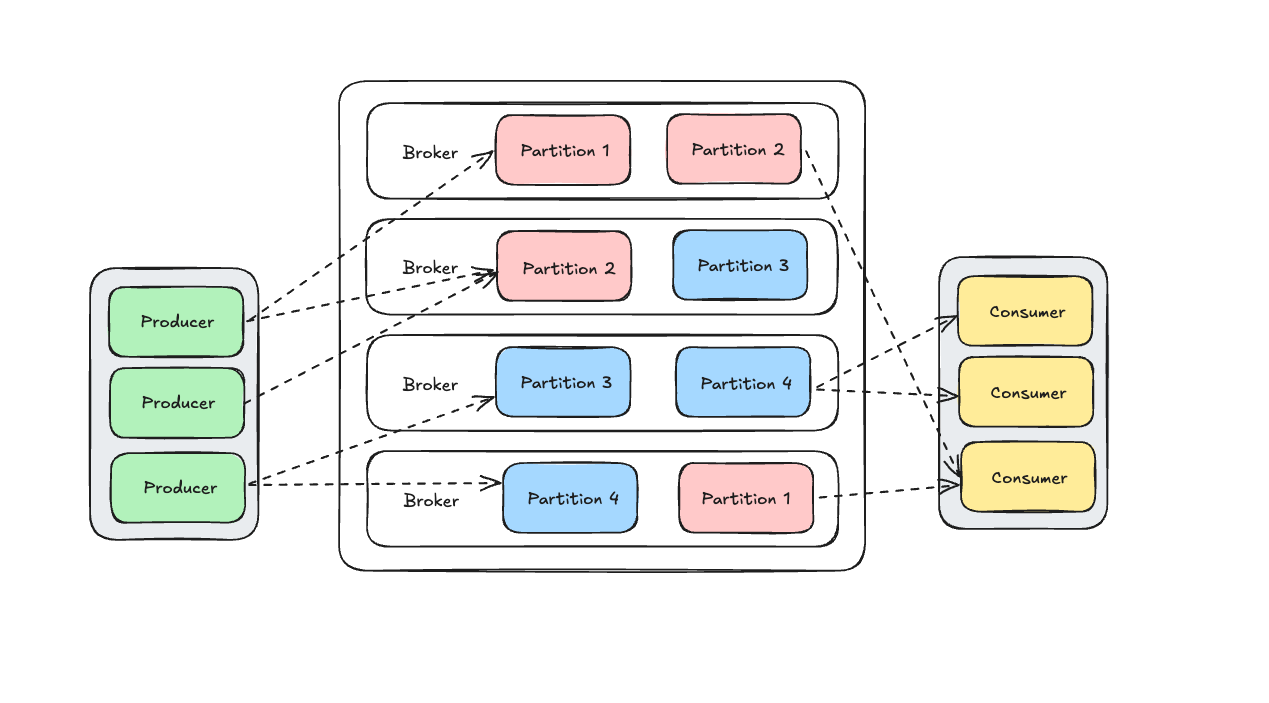
What’s important in this diagram isn’t just the arrows, but what they imply about Kafka’s design:
Producers don’t send messages directly to consumers. They write to partitions of a topic, which then act as the durable, ordered log.
Partitions are the unit of parallelism. In the diagram, multiple producers can write into the same topic, and Kafka will balance those writes across partitions.
Consumer groups scale horizontally. Notice how each consumer in a group is assigned its own partition. This ensures messages are processed once, without duplication, while still allowing throughput to scale as you add more consumers.
Replication under the hood (somewhat implied in the diagram) ensures that each partition has copies across brokers, so no single failure leads to data loss.
This diagram captures Kafka’s core promise: decoupling producers and consumers while guaranteeing order and fault tolerance through partitions and replication.
You can also read the actual initial white paper on Kafka’s conception here for more on architecture and initial design.
Why Kafka Shines
Kafka’s performance stems from its design specifically optimized for high-throughput, low-latency data streaming. It uses sequential disk I/O, which outperforms random access, and employs zero-copy techniques to reduce data copying between kernel and user space. This enables Kafka to handle millions of messages per second on commodity hardware. Kafka achieves immense scalability through partitioning (as aforementioned), where topics are split across multiple brokers, allowing parallel processing and supporting petabytes of data. Clusters can expand by adding brokers or partitions without interrupting operations.
Durability comes from replication, with each partition’s data mirrored across multiple brokers. If a broker fails, another seamlessly takes over, ensuring no data loss. Retention policies allow messages to persist for hours, days, or indefinitely, supporting both real-time streaming and historical analysis. This versatility suits a range of workloads: real-time event processing for monitoring, batch processing for analytics, or event-driven architectures for microservices.
Companies like Netflix leverage Kafka to process billions of events daily, driving real-time recommendations and system monitoring. LinkedIn, Kafka’s creator, uses it to handle massive activity streams. These use cases demonstrate Kafka’s ability to manage enormous data volumes with reliability and speed, making it a critical component for systems where data flows continuously and demands instant, fault-tolerant processing.
Kafka’s Idempotency Guarantee
One of Kafka’s most important abilities is that of ensuring idempotency. This is absolutely critical for applications where duplicate messages could cause chaos, like financial transactions or inventory updates. Idempotency means that processing the same message multiple times produces the same result as processing it once. Kafka achieves this through its idempotent producer feature, introduced to prevent duplicates without sacrificing performance.
Kafka does this in three key steps:
1. Producer IDs and Sequence Numbers
Each producer in Kafka is assigned a unique Producer ID (PID). Every message sent by that producer carries a monotonically increasing sequence number tied to the partition it’s writing to. The broker keeps track of these (PID, partition, sequence number) triplets, which allows it to detect and transparently discard duplicates if the same message ever arrives more than once.
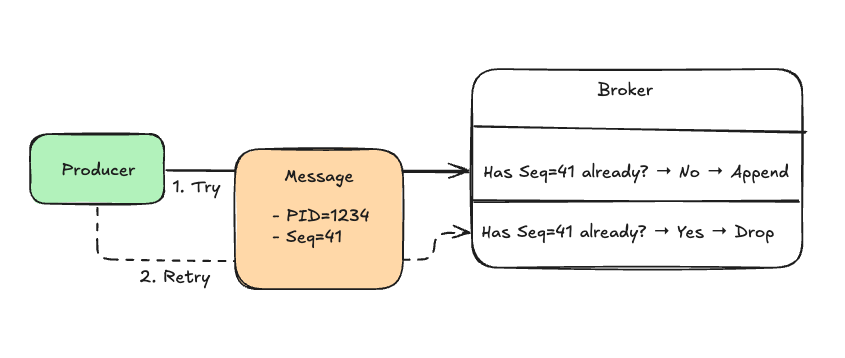
2. Broker-Side Deduplication
When a retry occurs, the broker performs a simple check: has this sequence number from this producer already been processed? If the answer is yes, the message is dropped; if not, the message is appended to the partition log. This mechanism provides exactly-once delivery semantics within a partition, even in the face of retries caused by network failures or broker restarts.
3. Application-Friendly API
From the application’s perspective, enabling this safety net is straightforward. You can turn on idempotency with a single configuration flag:
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");To get the most reliable behavior, this setting is usually paired with a few best practices: setting acks=all to ensure all replicas acknowledge the write, configuring retries=Integer.MAX_VALUE to allow safe retries, and limiting in-flight requests with max.in.flight.requests.per.connection=5 to prevent reordering issues. With these properties in place, Kafka takes care of deduplication automatically, eliminating the need for custom logic at the application level.
But Kafka’s idempotency has scope: it’s limited to a single producer session. If a producer restarts, it gets a new PID, and sequence tracking resets. On restart, a new PID/epoch invalidates the old in-flight state; brokers reject out-of-epoch appends. For stronger guarantees across multiple partitions or producers, Kafka provides the Transactions API, which extends idempotency into full exactly-once semantics (EOS). With transactions, you can bundle writes to multiple topics/partitions atomically. Somewhat like an “all or nothing” delivery.
Together, idempotent producers and transactions make Kafka a safe foundation for even the most sensitive workloads, like financial systems, where double-processing a message would be catastrophic.
Common Gotchas With Kafka
Kafka’s power comes with complexity, and missteps can derail its performance. Let’s go over some of the common gotchas with Kafka and how to counteract them:
1. Partitioning
Partitioning is a tricky, frequent pitfall. Too few partitions limit parallel processing, bottlenecking throughput; too many inflate overhead, slowing down coordination. A good starting point is one partition per consumer, adjusting based on observed throughput needs. Monitor metrics like messages per second to find the sweet spot.
2. Consumer Lag
When consumers can’t keep pace with producers, unprocessed messages pile up, delaying real-time insights. Scaling consumer groups by adding more instances or optimizing consumer logic, like batching reads, helps. Regularly check lag metrics via tools like Kafka’s built-in monitoring or third-party dashboards to catch issues early.
3. Retention Settings
Retention settings with Kafka are also pretty tough. Set retention periods too short, and critical data vanishes before processing; set them too long, and storage costs spiral. Align retention with business needs — short for transient events, longer for analytics requiring historical data. For example, my team uses a 14-day retention, which suits real-time apps with occasional reprocessing.
4. Coordination
Older Kafka versions relied on ZooKeeper for cluster coordination, adding setup and maintenance complexity. Newer versions use KRaft, a built-in consensus mechanism, simplifying deployments. When upgrading or starting fresh, opt for KRaft to reduce operational overhead. Tuning Kafka effectively requires vigilance. Make sure to consistently monitor performance, test configurations, and adjust iteratively to keep the system flowing.
Kafka’s Use Cases
Kafka’s versatility makes it a go-to for handling data in distributed systems. Here are some of the most common use cases for Kafka
1. Event-Driven Microservices
One prominent use case is event-driven microservices, where Kafka acts as a central hub for communication. Services publish events—like a user placing an order—to topics, and other services, such as inventory or notification systems, consume these events to react in real-time. This decouples services, enabling independent scaling and fault tolerance.
2. RTA
Real-time analytics is another key application. Kafka streams data to systems like Pinot, Spark, or Flink for processing, powering live dashboards or fraud detection. For instance, banks use Kafka to analyze transaction streams, flagging suspicious activity instantly. Log aggregation is also widespread, with Kafka collecting logs from distributed applications for centralized monitoring. Tools like the ELK stack integrate with Kafka to process and visualize system metrics efficiently.
3. Data integration
Data integration bridges disparate systems. Kafka connects legacy databases to modern cloud-native apps, syncing data like customer records or inventory updates. Kafka Connect, a framework for data ingestion, simplifies this by offering pre-built connectors for sources like SQL databases or APIs.
Kafka’s popularity really proves that Kafka is more than just theory. It’s been hardened and battle tested in production at massive scale. Companies like Uber rely on it to handle billions of trip events every day, while retailers use it to keep warehouses and online orders in perfect sync. These real-world deployments are the proof in the pudding: Kafka has been tested under some of the world’s most demanding data workloads, and it consistently delivers.
Closing Thoughts
Working with Kafka really changes how you think about systems. Instead of moving data around in isolated pipelines, you start to see it as an event stream that’s continuous, ordered, and durable. That shift opens the door to architectures that are more resilient, more decoupled, and ultimately easier to evolve.
But Kafka isn’t magic. The hard problems don’t disappear — they just get translated. Schema management, consumer lag, and partitioning strategy replace the spaghetti queues and ad-hoc pipelines of the past. It’s a better trade, but still one that demands discipline and care.
The most special thing about Kafka is that it has been proven at scale. The same technology that moves orders through a global retailer or coordinates billions of events for Uber can underpin your own systems if you treat it the right way. The companies that succeed with Kafka are the ones that see it not as middleware, but as core infrastructure: something to invest in, monitor, and build practices around.
If you have a great Kafka battle story, I’d love to hear about it in the comments!
And that brings us right back to where we started. In a world of digital traffic jams, dropped messages, lagging updates, and fragile pipelines, Kafka isn’t a silver bullet, but it is the road system you can trust.
Build on it carefully, and your data will flow.